PySpark est une bibliothèque qui permet d’utiliser Apache Spark avec le langage de programmation Python. Elle offre la possibilité de traiter rapidement et efficacement de très grandes quantités de données, ce qui en fait un outil essentiel pour les projets de Big Data. Grâce à PySpark, vous pouvez profiter de la puissance de calcul distribuée de Spark sans quitter l’environnement Python.
Pour bien comprendre PySpark, il est important de saisir les bases d’Apache Spark, de son architecture en cluster, de son mode de fonctionnement, ainsi que de la manière dont les données sont représentées et manipulées grâce aux DataFrames et aux RDD.
Apache Spark : Comment ça fonctionne ?
Apache Spark est un système distribué de traitement des données. Il découpe de lourds calculs en tâches plus petites, lesquelles sont réparties sur plusieurs machines (nœuds) travaillant en parallèle. Cette approche permet d’accélérer considérablement le traitement, en particulier lorsque le volume de données est très important.
La SparkSession : Point de départ en PySpark
Dans PySpark, la SparkSession est l’objet central à créer au début de chaque projet. Elle donne accès à toutes les fonctionnalités de Spark à partir d’une seule interface, incluant :
L’accès aux DataFrames, une structure de données organisée en lignes et colonnes.
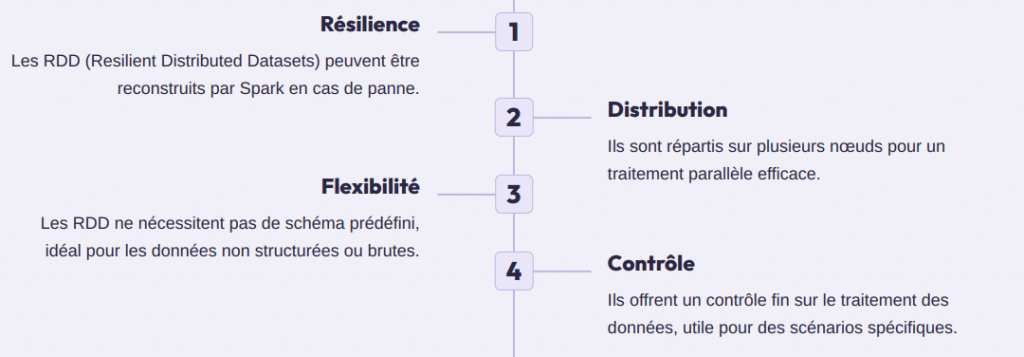
L’accès aux RDD (Resilient Distributed Datasets), une structure de données plus flexible et adaptée aux données non structurées.
Les capacités de gestion du cluster, telles que la création de tâches et leur envoi aux nœuds de travail.
Avant la SparkSession, il fallait créer manuellement un SparkContext pour interagir avec le cluster et les RDD. Désormais, la SparkSession intègre le SparkContext, ce qui facilite le développement en centralisant tous les points d’entrée dans un même objet.
Les principales structures de données : DataFrames et RDD
Les DataFrames sont conçus pour manipuler des données structurées (similaires aux tables relationnelles). Ils possèdent un schéma (définition précise des colonnes et de leurs types) et permettent des opérations de haut niveaufacilement compréhensibles, comme :
Filtrer des lignes
Sélectionner des colonnes
Joindre plusieurs tables
Effectuer des agrégations (moyennes, sommes, etc.)
Les DataFrames sont très bien optimisés, car Spark peut analyser les opérations demandées et les traduire en un plan d’exécution efficace. Le code est ainsi plus simple, plus clair, et les traitements plus rapides.
Les RDD sont la structure de données de base dans Spark. Ils représentent un ensemble distribué d’objets répartis sur le cluster. Contrairement aux DataFrames, ils ne nécessitent pas de schéma prédéfini, ce qui en fait un choix plus flexible pour les données non structurées ou brutes (fichiers texte, logs, flux non standardisés).
Les RDD : Flexibilité et puissance
Les RDD sont aujourd’hui moins utilisés au profit des DataFrames, qui sont plus simples et plus performants dans la plupart des cas. Cependant, ils restent indispensables pour certains scénarios spécifiques ou des besoins très fins de contrôle sur le traitement.
Transformations et actions : Mécanisme de calcul dans PySpark
Les transformations définissent des étapes de traitement (filtrer, mapper, trier, etc.) sur vos données. Ces opérations sont paresseuses (lazy) : elles ne s’exécutent pas immédiatement. Spark enregistre une suite d’étapes dans un plan d’exécution. Rien n’est réellement calculé tant qu’aucune action n’est demandée.
Par exemple, si vous enchaînez plusieurs transformations (filtrer, puis mapper, puis grouper), Spark attendra que vous lanciez une action pour exécuter l’ensemble de ces étapes de manière optimisée.
Les actions déclenchent l’exécution du plan de traitement accumulé par les transformations. C’est à ce moment-là que le calcul réel a lieu, en distribuant le travail sur le cluster. Parmi les actions les plus courantes, on trouve :
count() : Compte le nombre d’éléments.
collect() : Récupère toutes les données dans une liste (à utiliser avec précaution sur de très grands ensembles de données).
show() (uniquement pour DataFrames) : Affiche un aperçu des données.
L’évaluation paresseuse est un atout majeur : elle permet à Spark d’optimiser les traitements et d’éviter les calculs inutiles. Cette approche se traduit par un gain de temps et de ressources, surtout à grande échelle.
Conclusion
PySpark est un outil pratique pour traiter de grands volumes de données. Il combine la puissance d’Apache Spark et la simplicité de Python.
Que vous utilisiez des DataFrames pour des données structurées ou des RDD pour des cas plus flexibles, PySpark s’adapte à vos besoins en Big Data.
Nicolas Boillaud, Team leader Business App chez kaizzen