Dans un environnement numérique en constante expansion, la recherche documentaire joue un rôle essentiel pour exploiter les données disponibles de manière efficace. Cependant, garantir la pertinence des résultats reste un défi majeur, surtout lorsque le volume de données augmente de manière exponentielle.
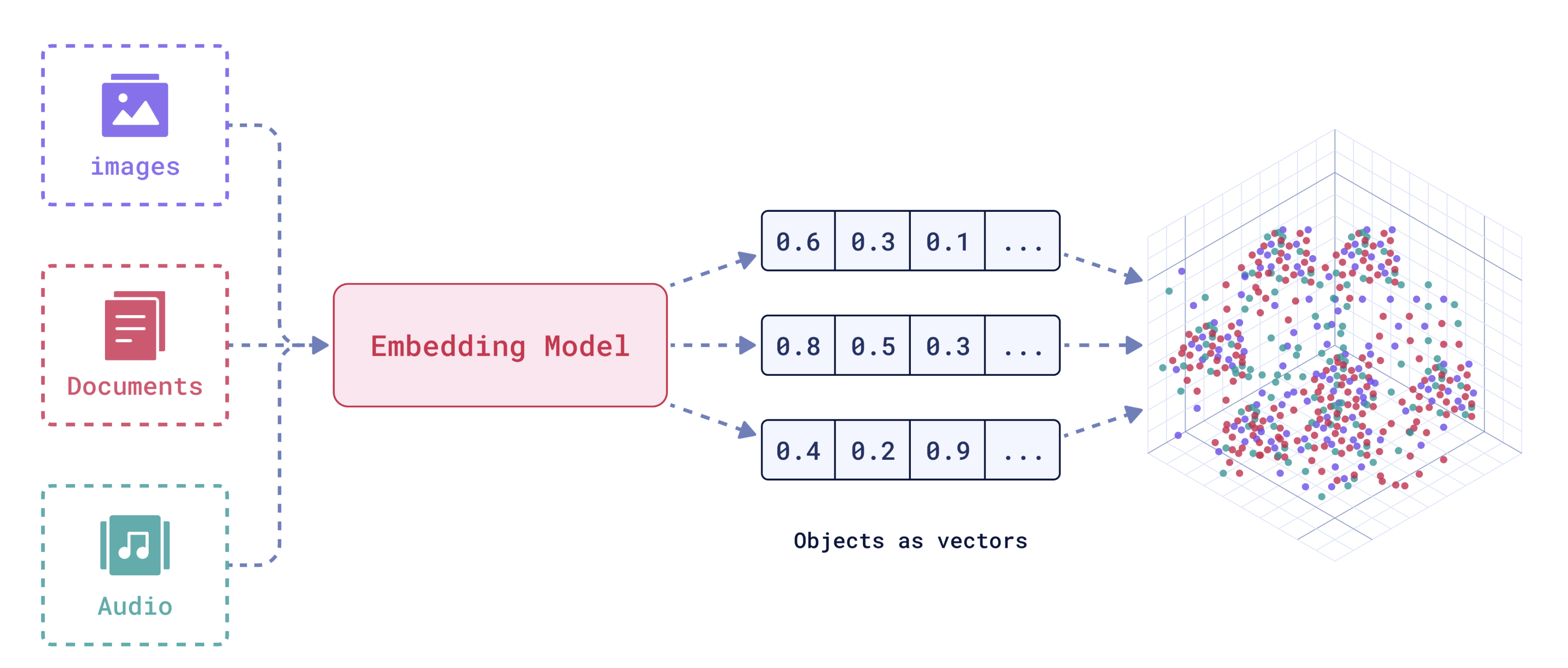
Les embeddings (ou vecteurs numériques) sont des représentations mathématiques d’objets (ou tokens), comme des mots, des phrases ou des images, sous forme de vecteurs de nombres dans un espace de dimensions réduites. Les tokens ayant des significations similaires ont des vecteurs proches dans l’espace.
Les modèles d’embeddings, comme ceux proposés par OpenAI tels que text-embedding-ada-002, permettent de représenter le contenu textuel sous forme de vecteurs numériques, dits aussi embeddings, offrant ainsi une base solide pour une recherche sémantique avancée. Cependant, les approches classiques, telles que la similarité cosinus appliquée aux embeddings, bien qu’efficaces dans certains contextes, montrent rapidement leurs limites en termes de performancesur des bases de données volumineuses et/ou complexes.
Contexte et problématique
Comment optimiser la recherche documentaire pour garantir des résultats plus pertinents et efficaces dans des bases de données massives, tout en surmontant les limites des méthodes classiques comme la recherche basée sur le calcul de la similarité cosinus ?
Facebook AI Similarity Search
C’est dans ce contexte que FAISS (Facebook AI Similarity Search) se distingue comme une solution innovante, offrant des recherches rapides et scalables, optimisant la recherche documentaire et facilitant la gestion efficace des données textuelles à grande échelle.
FAISS est une bibliothèque open-source spécialisée dans la recherche des plus proches voisins dans des ensembles de vecteurs. La solution offre une large gamme d’index adaptables aux besoins spécifiques, tels que IndexFlatL2 pour une précision maximale, contrairement à la recherche basée sur le calcul de la similarité, qui est peu personnalisable et lente.
Vers une recherche optimisée
Recherche par Prompt avec OpenAI
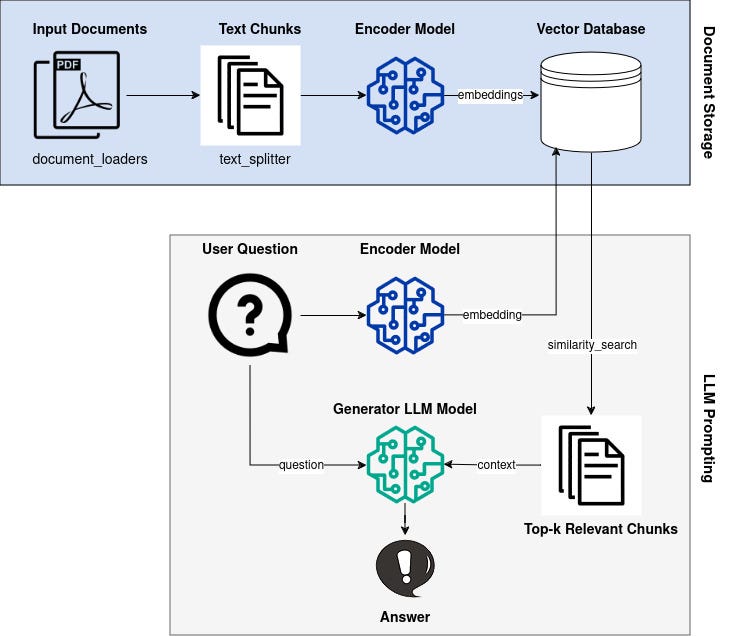
La recherche documentaire repose ici sur des prompts envoyés à OpenAI, où les modèles avancés comme text-embedding-ada-002 transforment les requêtes et les documents en vecteurs. Ces prompts permettent d’exploiter les capacités des modèles pour rechercher des documents non pas simplement en fonction de mots-clés, mais en capturant la sémantique des contenus textuels.
FAISS (Facebook AI Similarity Search)
Une fois les embeddings générés pour les prompts, FAISS intervient pour exécuter la recherche vectorielle à grande échelle.
Indexation des Vecteurs : Les vecteurs résultants des prompts sont stockés dans des index FAISS pour faciliter la recherche rapide.
Recherche KNN (K Nearest Neighbors) : FAISS utilise des algorithmes approximatifs pour identifier les K vecteurs les plus proches de celui généré par un prompt spécifique.
Exemple Kaizzen
Exemple de réponse avant FAISS
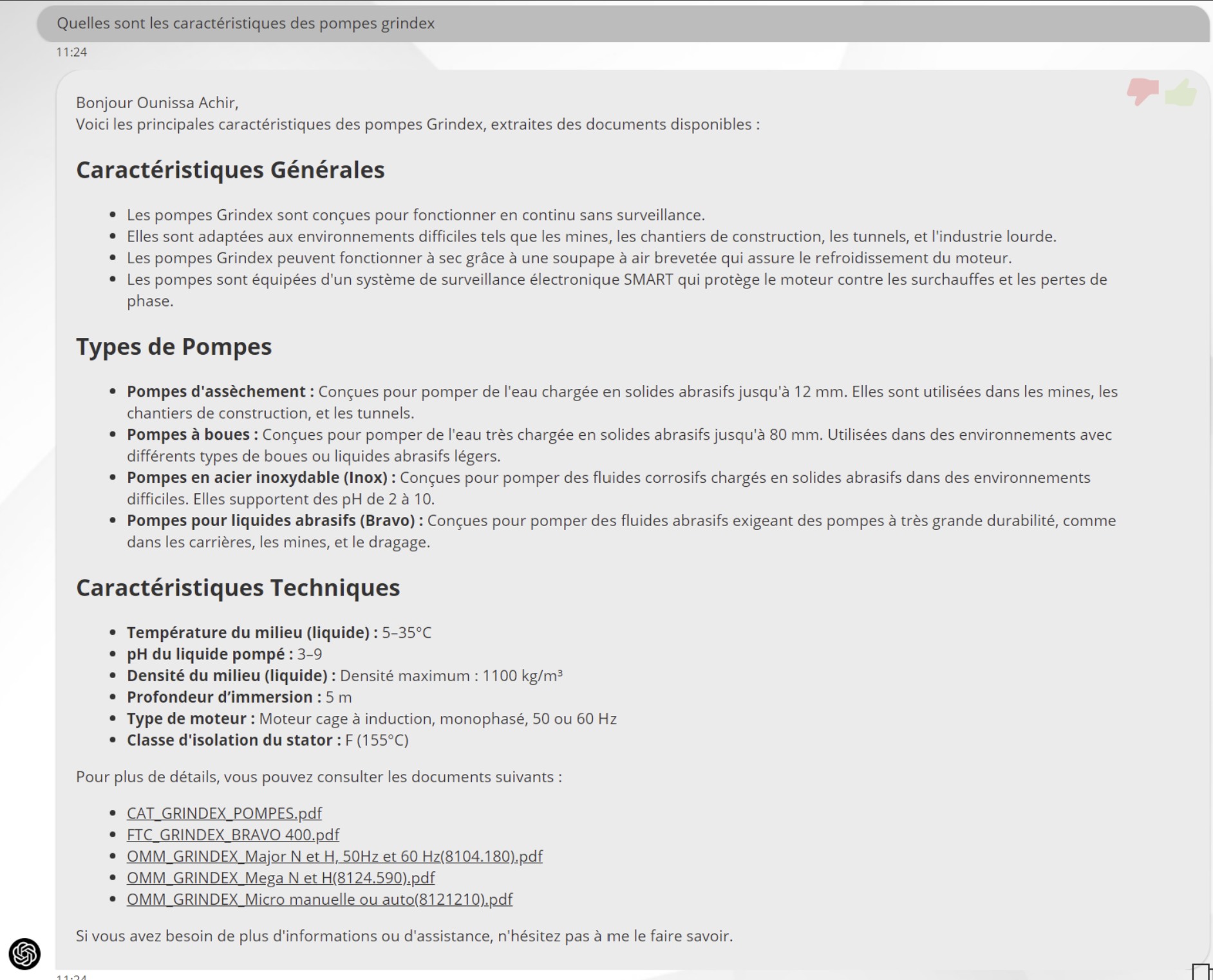
Exemple de réponses après FAISS
Les deux figures représentent les réponses générées par le modèle GPT-4 mini avant et après l’intégration de FAISS.
Avant FAISS ou la recherche documentaire par la similarité cosinus : la réponse est plus générale, moins détaillée et moins technique. Elle manque de précision et n’exploite pas pleinement les connaissances disponibles.
Après FAISS : la réponse est nettement plus détaillée et technique. FAISS permet d’améliorer la recherche d’information, ce qui se traduit par une réponse plus riche en contenu pertinent, plus précise et mieux structurée.
En résumé, l’utilisation de FAISS améliore considérablement la qualité des réponses en fournissant des éléments plus approfondis et spécialisés.
Conclusion
La transition vers FAISS marque une avancée majeure dans le domaine de la recherche documentaire. Sa capacité à traiter rapidement et efficacement des bases de données volumineuses en fait une solution incontournable pour les entreprises cherchant à optimiser leurs processus d’information.
Adopter FAISS, c’est opter pour une technologie qui transforme les défis en opportunités, permettant aux entreprises de rester compétitives et innovantes dans un monde axé sur les données.